이번 프로젝트 때 Kafka를 사용하여 비동기 처리 및 알림 시스템을 개발하게 되어서 개발에 들어가기 전에 확실히 이해하고자 포스팅

Kafka
Kafka는 분산 스트리밍 플랫폼으로 주로 실시간 데이터 피드의 빅 데이터 처리를 목적으로 사용된다.
메시지 큐와 유사하지만, 대용량 데이터 스트림을 저장하고 실시간으로 분석하거나 처리하는데 더 중점을 둔다.
장단점
| 장점 | 단점 |
| 데이터 복제 데이터를 여러 브로커에 복제하여 저장하므로 데이터 손실 방지 확인 메커니즘 데이터가 소비자에게 성공적으로 전달되었는지 확인하는 기능 제공 다양한 소비자 패턴 여러 소비자가 동시에 데이터를 구독 할 수 있음 프로토콜 지원 다양한 클라이언트를 통해 다른 언어에서도 사용 가능 분산 시스템 클러스터링을 통해 여러 노드에서 데이터를 분산 처리 수평 확장 브로커와 파티션을 추가하여 쉽게 확장 높은 처리량 대용량 데이터를 실시간으로 빠르게 처리 저지연 데이터 전송의 지연을 최소화하여 실시간 처리 가능 관리 도구 다양한 관리 도구를 통해 클러스터를 모니터링하고 관리 할 수 있음 플러그인 시스템 다양한 플러그인을 통해 기능을 확장 할 수 있음 |
복잡한 설정 초기 설정이 다소 복잡할 수 있으며, 클러스터링 및 분산 환경에서는 더 많은 설정 필요 운영 관리 대규모 환경에서 운영하고 관리하는데 추가적인 노력 필요 브로커 오버헤드 높은 트래픽 상황에서는 브로커의 오버헤드 발생 우려 대규모 메시지 처리 보다 더 대규모의 메세지를 처리할 때 성능 저하가 발생할 수 있으며 이러한 경우 적절한 클러스터링 및 최적화 필요 리소스 소비 메모리와 CPU 자원을 많이 소비할 수 있어 충분한 리소스가 제공되어야 원활하게 운영 가능 모니터링 및 유지보수 지속적인 모니터링과 유지보수가 필요하기 때문에 이를 위한 인력과 비용 추가 발생 학습 필요성 개념과 설정을 이해하는데 시간이 걸릴 수 있으며 다소 난이도가 있음 |
Kafka의 기본 요소
✔️ Topic, Producer, Consumer

- Producer : 메시지를 생산해서 Kaffa의 Topic으로 메시지를 보내는 애플리케이션
- Consumer : Topic의 메시지를 가져와서 소비하는 애플리케이션
- Consumer group : Topic의 메시지를 사용하기 위해 협력하는 Consumer들의 집합
- 하나의 Consumer는 하나의 Consumer Group에 포함되며, Consumer Group내의 Consumer들은 협력하여 Topic의 메시지를 분산 병렬 처리함 → 스티키 파티셔닝 Sticky Partitioning 사용.
✔️ Producer와 Consumer의 기본 동작 방식

Commit Log : 추가만 가능하고 변경 불가능한 데이터 구조, Event(데이터)는 항상 로그 끝에 추가되고 변경되지 않음.
Offset : Commit Log에서 Event의 위치. 위 그림에서는 0부터 10까지의 Offset이 있음.
프로듀서와 컨슈머는 서로 알지 못 하며, 각각 고유의 속도로 Commit Log에 Write 및 Read를 수행
다른 컨슈머 그룹에 속한 컨슈머들은 서로 관련이 없으며, Commit Log에 있는 Event를 동시에 다른 위치에서 Read 가능.
✔️ Commit Log에서 Event 위치

프로듀서가 Write하는 LOG-END-OFFSET과 컨슈머가 Read하고 처리한 후에 Commit한 CURRENT-OFFSET과의 차이가 발생 할 수 있다. → Consumer Lag
✔️ Logical View ( Topic, Partition, Segment )
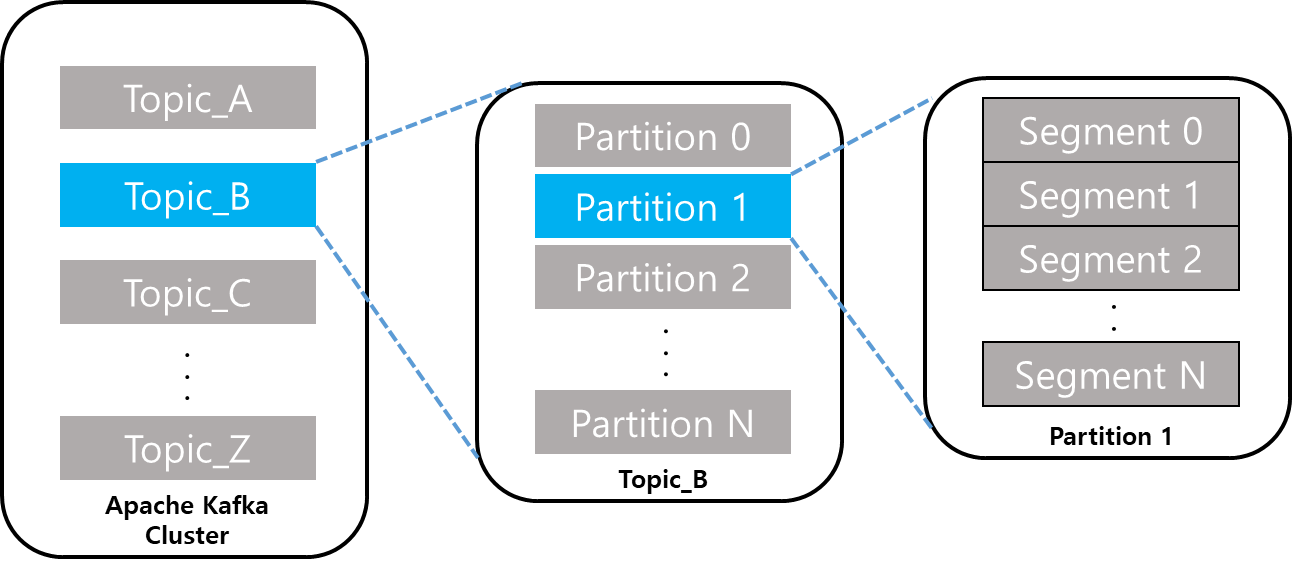
- Topic : Kafka 안에서 메시지가 저장되는 장소, 논리적인 표현
- Partition : 파티션은 토픽을 물리적으로 나눈 단위. 하나의 Topic은 하나 이상의 Partition으로 구성, 병렬처리(Throughput 향상)를 위해서 다수의 Partition을 사용. 파티션 내의 메시지는 고유한 오프셋 offset으로 식별.
- Segment : 메시지(데이터)가 저장되는 실제 물리 File, Segment File이 지정된 크기보다 크거나 지정된 기간보다 오래되면 새 파일이 열리고 메시지는 새 파일에 추가됨
✔️ Physical View ( Topic, Partition, Segment )
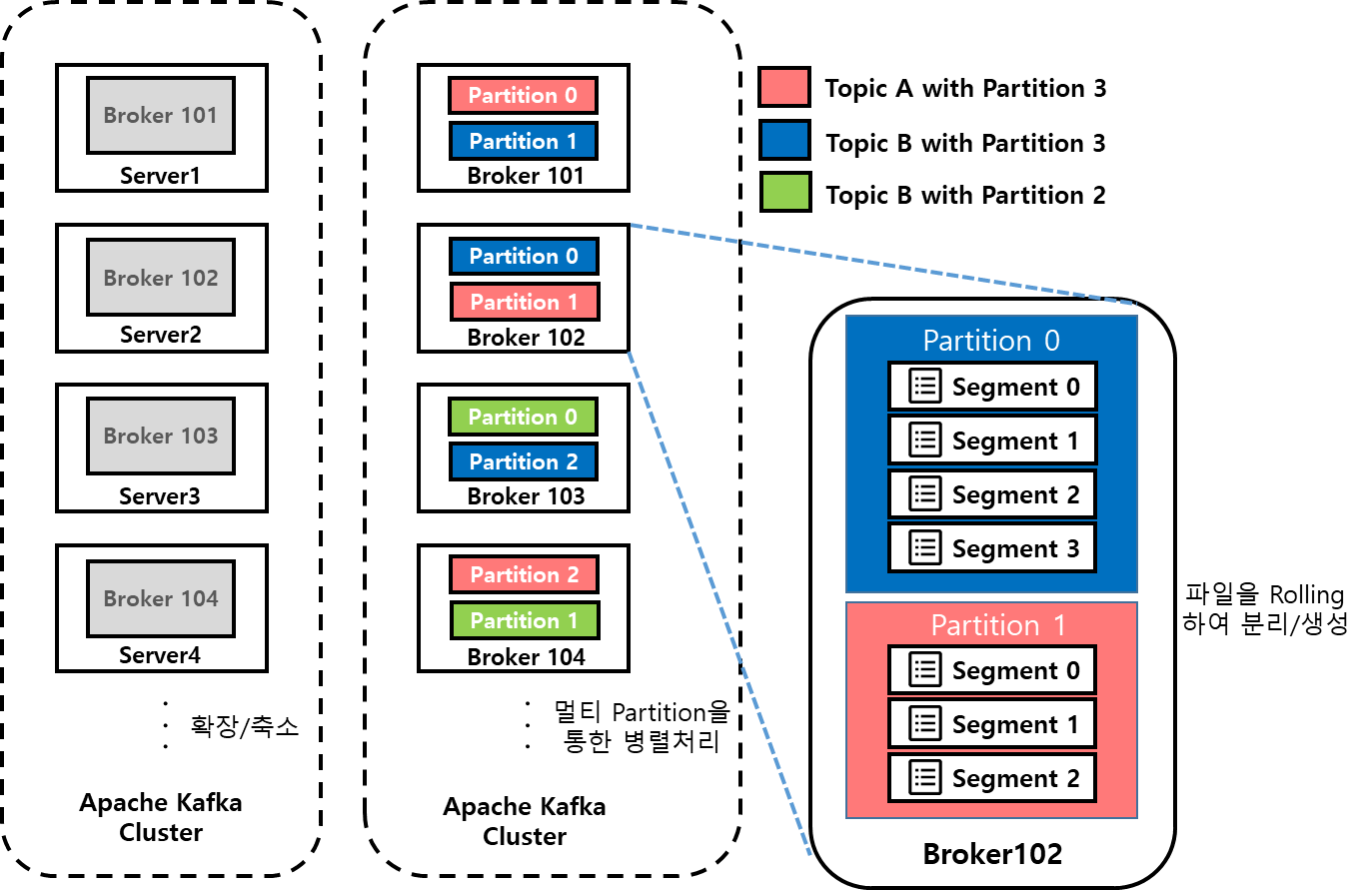
- Topic 생성시 Partition 개수를 지정하고, 각 Partition은 Broker들에 분산되며 Segment File들로 구성됨
- Rolling Strategy: Log.segment.bytes(default 1 GB), log.roll.hour(default 168 hours)
✔️ Partition 당 하나의 Active Segment

- Partition당 오직 하나의 Segment가 Active 되어 있음 -> 데이터가 계속 쓰여지고 있는 중
🔗 참고 포스팅
https://velog.io/@kidae92/Apache-Kafka-%EC%A3%BC%EC%9A%94-%EC%9A%94%EC%86%8C1Producer-Consumer-Topic
Apache Kafka 주요 요소1(Producer, Consumer, Topic, Partition, Segment)
1\. Topic, Producer, ComsumerProducer: 메시지를 생산해서 Kaffa의 Topic으로 메시지를 보내는 애플리케이션Consumer: Topic의 메시지를 가져와서 소비하는 애플리케이션Consumer group: Topic의 메시지를 사용하기
velog.io
'DevOps' 카테고리의 다른 글
| [✉️ Kafka] Kafka 설치 및 예제로 실습해보기 (2) | 2024.09.27 |
|---|---|
| [✉️ Kafka] Kafka 이해하기2 - Zookeper, Broker, Message (2) | 2024.09.27 |
| Docker로 pgAdmin 띄워서 PostgreSQL 손쉽게 활용하기 (1) | 2024.09.25 |
| Redis와 NoSQL, Redis의 데이터 타입 이해하기 (0) | 2024.08.21 |
| Dockerfile & Docker Compose 사용하기 (0) | 2024.08.20 |